Knowledge Byte: Who and What You Should Be Involving in a Big Data Project

Cloud Credential Council (CCC)

C-Suite members need to be involved from the start and they need to provide support in terms of resources and politics. Big Data projects are new, different, and perceived as risky.
● Domain experts are necessary to help define the problem better and point to potential data sources. They’ll also be able to assess the output and provide recommendations on how to improve it.
● “Scary data people” are the actual analysts. They possess a mixture of skills – mathematics or statistics, business expertise, some IS knowledge, for example, SQL, and so on. They are more likely to come from the business side and, ideally, will have experience across more than one area, for example, marketing, finance, and so on.
● IT professionals will perform the more traditional roles of designing and maintaining the Big Data infrastructure.
What Is Involved?
The following stages are involved in the Big Data projects:
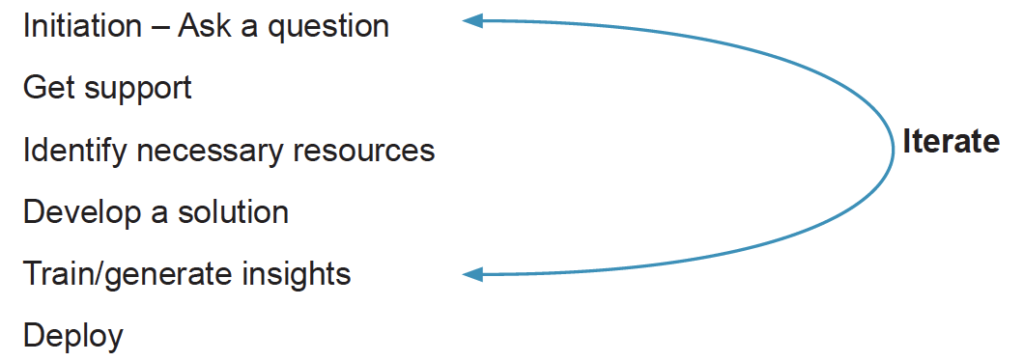
● Initiation – During this phase, the business question(s) need(s) to be defined. Well defined question(s) will result in a detailed scope.
● Get support – Like any other project, a Big Data project will need a project sponsor with the required amount of influence within the organization. Regardless of how well the planning was done, at certain points in the initiative, competition for resources will occur, e.g. access to DB administrators who are working on a different project. In these cases, an influential sponsor will be able to resolve the situation in the most beneficial way for everyone involved.
● Identify resources – A Big Data project is likely to involve people from several areas of the organization, e.g. business analysts, DB administrators, system administrators, and subject matter experts. Being able to identify the required resources and when and for how long they will be available will provide the organization with certainty and ensure the availability of resources. For example, a DBA may be needed for 2 hours every fortnight, while a subject matter expert may be needed for 2 hours every week. This stage will also include identifying the infrastructure, e.g. a VM with 8GB RAM and 4-core i7 CPU.
●Develop a solution – This stage will involve a decision on what Big Data tools will be used, what data mining algorithms will be evaluated, and how data will be structured.
● Train/generate insights – Train data mining algorithms and deploy them on testing data. Datasets need to be split into training and testing part to ensure that algorithms work as necessary. All insights need to be discussed with subject matter experts to determine what is valid and what is an aberration/coincidence.
● Deploy – In this stage, the Big Data solution, including data mining, will be provided to business users to include in their workflow.
Politics:
● Cut across silos – Departments are very protective of “their” data. It is a usual occurrence for HR not to share their data with Finance and vice versa. Big Data, inherently, uses data that belongs to different departments and needs to be combined to create new value.
● IS disenfranchised – Up until now, any data questions/initiatives/issues were the domain of IS. At present, however, data can come from many sources and only some of these, for example, enterprise data are under the management of IS. This may create tensions since IS are the “go-to” people in relation to data and information any more.
● Initiatives are different – People within the organization may be confused by Big Data projects. Such projects involve a lot of external data, new ways of thinking, and new ways of doing things, e.g. data mining vs creating SQL queries.
Courses to help you get
results with Big Data
Sorry, we couldn't find any posts. Please try a different search.
Never miss an interesting article
Get our latest news, tutorials, guides, tips & deals delivered to your inbox.
Keep learning


