Knowledge Byte: What Characterizes Big Data?

Cloud Credential Council (CCC)

Volume
The first characteristic of Big Data that we are going to discuss is volume. When discussing volume, first we need to define how it is measured. As consumers and professionals, we are familiar with terms such as kilobyte, megabyte, and gigabyte. However, Big Data volumes go well beyond any of these quantities. Thus, a definition is warranted at this stage.
The list below provides the exact measurement of the terms used to measure data quantities, expressed as bytes, at present:

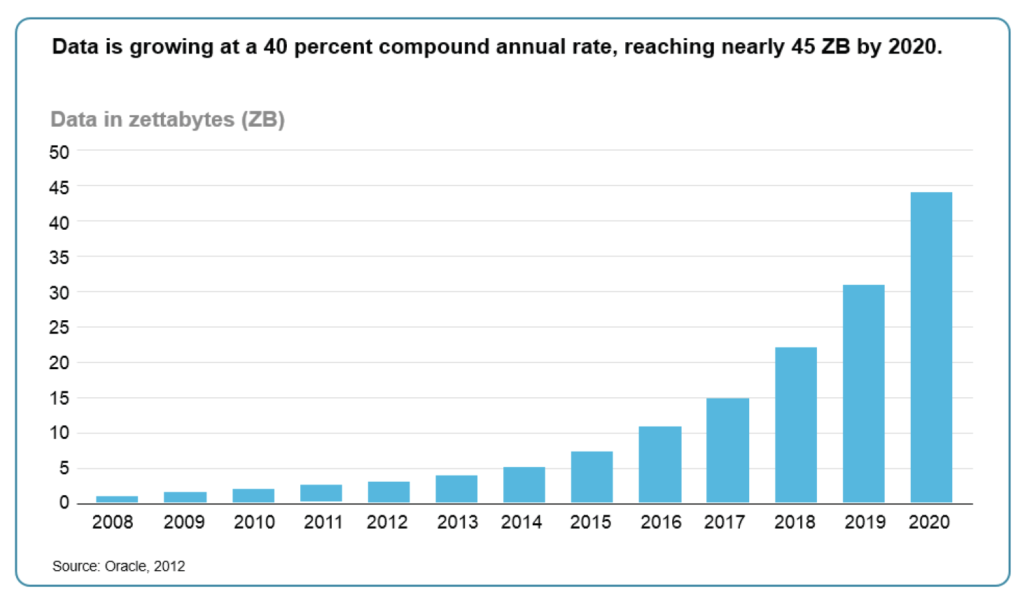
● According to IBM, approximately, 2.5 exabytes of data are created every day. 90% of the data in the world was created in the last 2 years (source: Science Daily – 22 May 2013).
● MGI estimates that 15 out of 17 sectors in the US have more data stored per company than the US Library of Congress (source: MGI – Big Data: The Next Frontier).
Velocity
Velocity is the second characteristic of Big Data. We know that volumes are increasing at a very rapid speed, but what is the extent of this increase and how are we able to respond to this increase? To answer these questions, we will consider two scenarios.
LinkedIn mines petabytes of data to produce a “People you may know” list (Source).
Scenario 1 – Social Media
This list needs to be produced within 10 to15 seconds of a user’s visit to the page. Any longer than 10 to 15 seconds may lead to alienation of the visitors and reduction of their visit to the site. On the other hand, LinkedIn cannot afford not to produce this list. The value of a customer is influenced greatly by the size of their network. If the customers stop growing their networks, LinkedIn’s business model will be seriously jeopardized.
Scenario 2 – Fraud
Let’s imagine the following situation – A withdrawal is made from an ATM in New York. Sometime later, let’s say 30 minutes later, using the same card, a withdrawal is made from an ATM in London. Clearly, moving physically from New York to London, within 30 minutes is not possible. Fraud is the most likely reason for this to happen.
In order to identify this situation, a monitoring system needs to process millions of transactions within a very short time. It is estimated that approximately 100 million transactions occurred per day in the US in 2006 (Source).
Variety
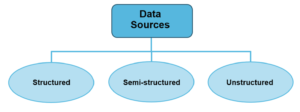
Variety is another characteristic of Big Data. When we talk about Big Data, variety refers to the types of data sources that need to be processed. The three main types of data sources that we need to deal with are structured, semi-structured, and unstructured.
Structured – This data resides within enterprise systems and its structure is well defined. Examples include payroll, finance, or other ERP systems. In such systems, a database, usually relational, is used to store data. As a result, data is stored in tables with a structure that has been determined during the design phase. This data is persistent and is the same for each record. An example of such a data record is the employee record in an HR system. It will contain at least the employee ID, first name, last name, and other fields, as required.
Semi-structured – This data is characterized by large volumes, the small size of individual records, and simple record structure. An example would be the data sent by an intelligent power meter to a central system. Each packet has the same structure, such as: timestamp – 10 bytes, location – 10 bytes, and consumption – 10 bytes. Thus, in 30 bytes, information about electricity consumption is stored. The 30 bytes is misleading since the daily volume in a city of 500,000 households with 5-second intervals will be 4.32GB (30*12*24*500000).
Unstructured – In this case, though the data is called “unstructured”, it is still structured. However, this is called unstructured because in this case, we are dealing with a large number of different structures. Examples here include data coming from social media, such as audio, video, graphics, and text. Additionally, the data coming from enterprise sources, outside enterprise systems, such as Word files, emails, PDFs are also included here. This is the fastest-growing segment of data.
Courses to help you get
results with Big Data
Sorry, we couldn't find any posts. Please try a different search.
Never miss an interesting article
Get our latest news, tutorials, guides, tips & deals delivered to your inbox.
Keep learning


